1 Bakgrunn
1.1 Kunnskapsbasebaserte Språkmodeller
Kunnskapsbasebaserte Språkmodeller (KBS), oversatt fra Retrieval-Augmented Generation, er en teknikk for å inkorporere ekstern eller ny informasjon når en stor språkmodell skal generere svar. Uten KBS vil en stor språkmodell generere svaret sitt basert på informasjon den plukket opp under opptrening. Fordelen med dette er at informasjonen er innebygget i modellen og det er enklere for modellen å bruke kunnskapen (ikke zero-shot learning). Bakdelen med dette er at det tar lang tid å trene opp, samtidig som opptrening er en kostbar prosess. Med KBS bruker vi deler av kontekstvinduet (se Definisjon D.3) til å fylle inn informasjon fra en kunnskapsbase. Dette gir språkmodellen tilgang til ekstra informasjon, man slipper å dele kunnskapsbasen med tilbyder av språkmodellen (språkmodellen trenger ikke å trenes på kunnskapsbasen), samtidig som det har vist seg å redusere hallusinering1 for språkmodellen. Det gjør også mulig at kunnskapsbasen og språkmodellen kan utvikle seg uavhengig av hverandre og kunnskapsbasen kan oppdateres med ny informasjon uten at språkmodellen trenger å endre seg. Bakdelen med KBS er at språkmodellen må kunne klare å hente ut informasjon fra konteksten, noe som kan være utfordrende med mindre språkmodeller, samtidig som vi bruker plass i kontekstvinduet som kunne vært brukt til chat-historikk.
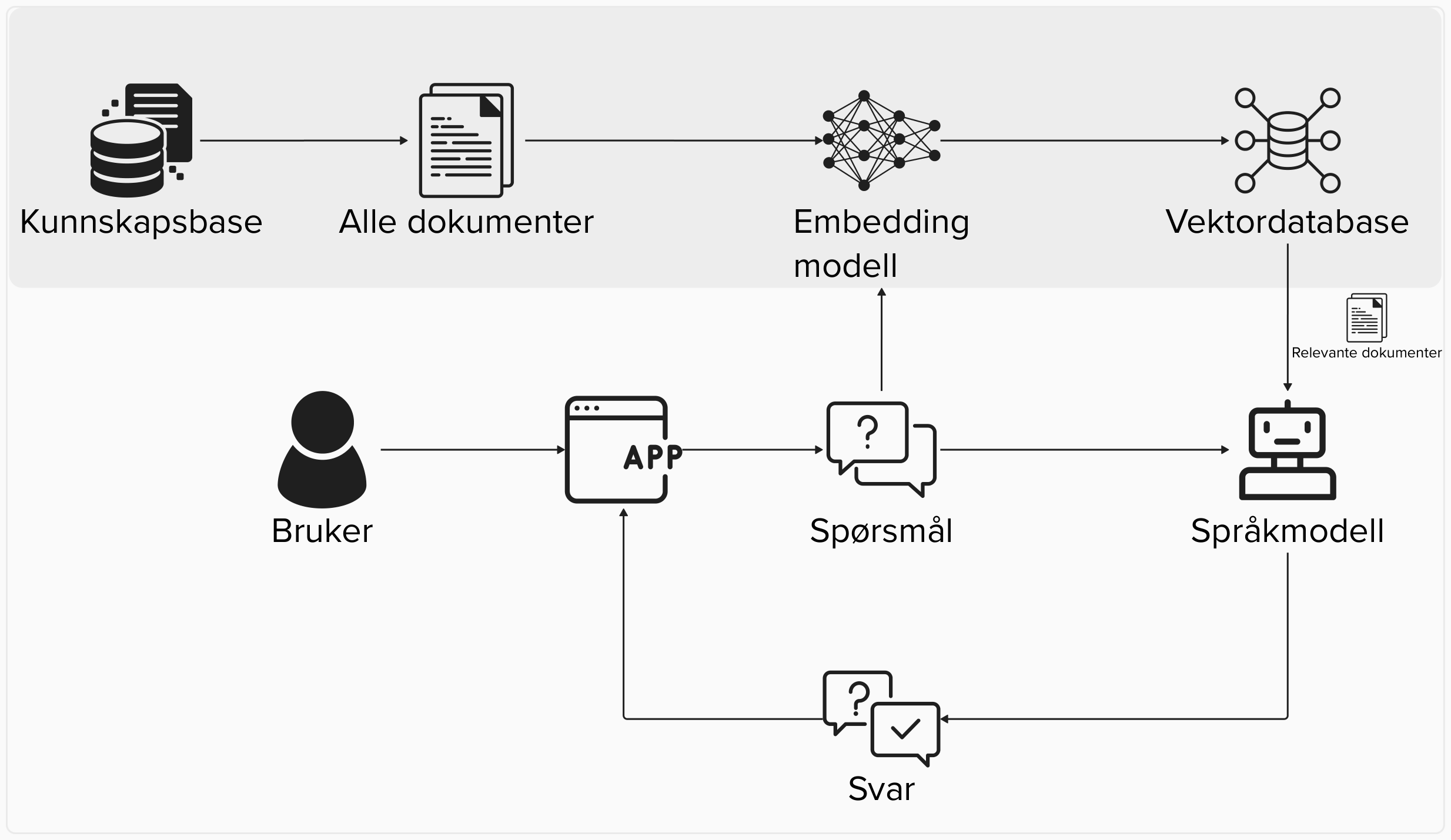
I Figur 1.1 er det illustrert hvordan flyten går fra bruker stiller spørsmål til språkmodellen som benytter både spørsmålet samt relevante dokumenter som input for å generere et svar.

En utfordring med KBS er hvordan man skal organisere kunnskapsbasen slik at relevante dokumenter kan inkorporeres i konteksten til den store språkmodellen. Hvordan søket utføres vil ha stor innvirkning på kvaliteten på det genererte svaret ettersom KBS ofte krever at språkmodellen bare svarer på bakgrunn av dokumentene i konteksten. I teorien er det ikke noe i veien for å bruke et mer tradisjonelt søk etter dokumenter, ala Google søk. I oppsettet til Azure/Vertex AI er det derimot satt opp til at man bruker en vektordatabase som finner relevante dokumenter2.
1.2 Vektordatabase
I konteksten av KBS er en vektordatabase en måte å lagre en indeks over dokumenter som sammenfaller med måten språkmodellen forstår tekst. Som navnet tilsier er en vektordatabase en database med vektorer, det spesielle i konteksten av KBS er at disse vektorene er generert med en modell som er trent på en lignende måte som en stor språkmodell. Med andre ord, dokumentene i kunnskapsbasen indekseres med en feature vektor av inneholde deres, generert fra en embedding modell (se Definisjon D.2 og neste seksjon). Merk at embedding modellen er uavhengig av språkmodellen i bruk. Ofte brukes en embedding modell som sammenfaller med språkmodellen, f.eks. brukes OpenAI sin embedding modell sammen med GPT-4, men det er absolutt ingen krav3.
I Figur 1.2 er det illustrert hvordan kunnskapsbasen og vektordatabasen henger sammen for å hente frem relevant kontekst for språkmodellen. I figuren vises sammenhengen mellom embedding modellen og vektordatabasen, både indeksen til vektordatabasen blir laget på bakgrunn av embedding modellen samtidig som spørsmålet til brukeren går gjennom embedding modellen for å søke i vektordatabasen. Merk at vektordatabasen oppdateres uavhengig fra språkmodellen som tilrettelegger for oppdatert informasjon fra kunnskapsbasen.
Som nevnt i forrige seksjon så er det ingen absolutte krav til at språkmodellen må jobbe med en vektordatabase. I realiteten henter vi rådokumentene fra kunnskapsbasen når vi fyller inn kontekstvinduet til språkmodellen. Med andre ord, vi bruker bare feature vektorene og embedding modellen til å søke, ikke som faktisk input til språkmodellen. På grunn av begrensninger i kontekstvinduet til språkmodeller kan vi heller ikke bruke for mange dokumenter og det er derfor viktig at kunnskapsbasen har høy dekning (eller sensitivitet). De fleste tilbydere av språkmodeller tar også betalt for antall token i input til modellen, noe som også gir et insentiv for å begrense antall dokumenter.
1.2.1 Hybridsøk
Både Azure OpenAI og Vertex AI tilbyr egne databaser for søk sammen med språkmodeller. Argumentet for å bruke disse databasene sammenlignet med self-hosting eller lignende er at både Azure og Vertex AI tilbyr forbedret søk, noe som er veldig viktig i en KBS kontekst. Bakdelen med disse databasene er at man mister litt av kontrollen over databasen til tilbyder, samtidig som det er en ekstra kostnad som må tas hensyn til. Det er derfor viktig å teste om de ekstra tjenestene som tilbys gir mer verdi i sammenheng med kunnskapsbasen som det skal søkes i.
Måten disse hybride søkene fungerer er ved å kombinere vektorsøk med mer tradisjonelle søkemetoder som for eksempel BM25. Dette krever mer regnekraft og kan dermed være tregere, men til gjengjeld gi bedre dekning. Det er i utgangspunktet ikke noe i veien for å implementere de samme søkene manuelt og avveiningen blir naturlig nok mellom tid og penger.
I Azure AI Search kan man selv styre hvordan databasen skal operere. Ved bruk av hybrid vil den operere som beskrevet i denne seksjonen, men ved bruk av similarity vil den operere som en ren vektordatabase. Vær varsom med å benytte riktig søk og i Nav sammenheng vurder andre databaser hvis bare similarity benyttes.
1.3 Embedding modell
Et konsept som ofte blir brukt i forbindelse med KBS og språkmodeller er såkalte embedding modeller (se Definisjon D.2). En embedding modell har som oppgave å ta inn et ord eller en tekst og returnere en vektor som representerer den semantiske meningen til inputen. Embedding modeller er ikke noe nytt innenfor språkteknologi, men det brukes ofte sammen med vektordatabaser slik at vektorene representerer det semantiske innholdet til en tekst, som beskrevet i forrige seksjon. Ved å ha en abstrakt representasjon av det semantiske innholdet vil man kunne sammenligne, se på forskjeller eller gjøre andre operasjoner på vektorene.
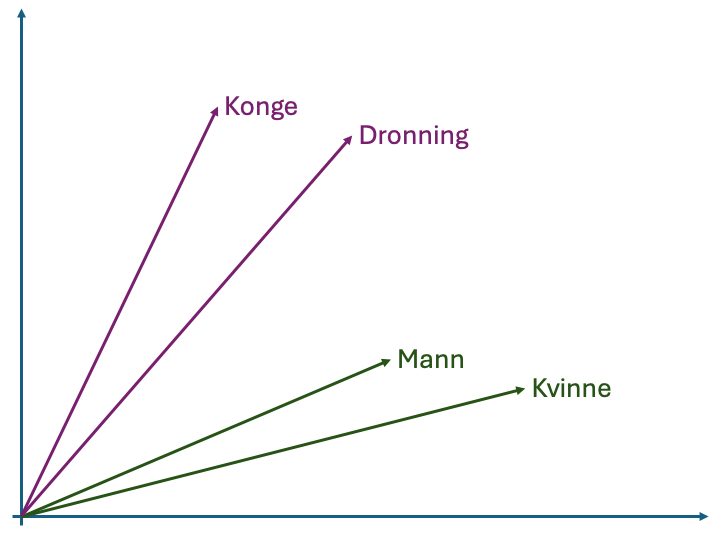
Et eksempel på en operasjon vi kunne ønske å gjøre i vektorrommet er å finne det tilsvarende ordet for Konge for en kvinne. I bildet i margen kan dette illustreres ved å generere en vektor mellom Mann og Konge. Deretter legger vi denne vektoren til punktet for Kvinne og velger det nærmeste ordet. I bildet i margen tilsvarer dette Dronning og vi returnerer det som svar. Merk at disse operasjonene bare utføres i det abstrakte vektorrommet og vi forholder oss ikke til de faktiske ordene. Dette gjør for eksempel at vi kunne ha gjort operasjonene i motsatt retning og funnet et ord som tilsvarer forskjellen mellom Konge og Mann for Dronning.
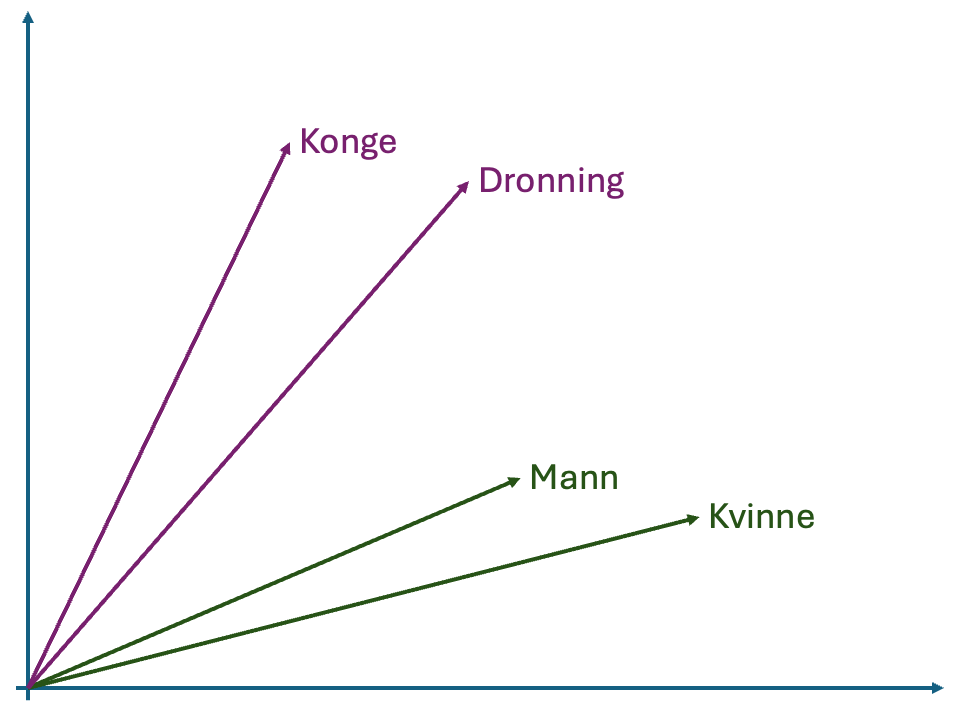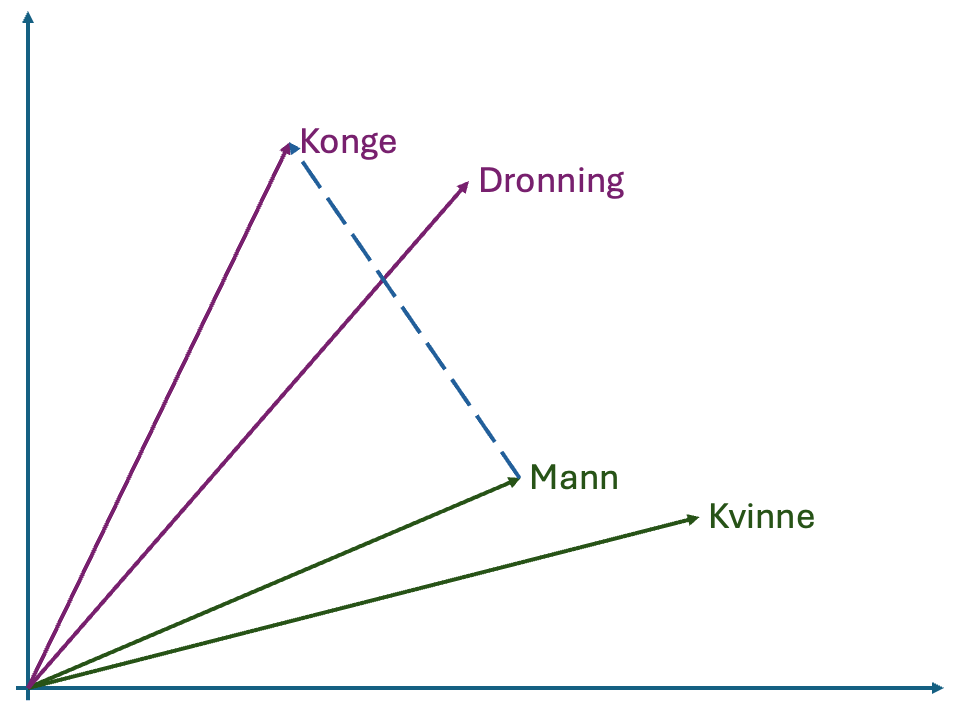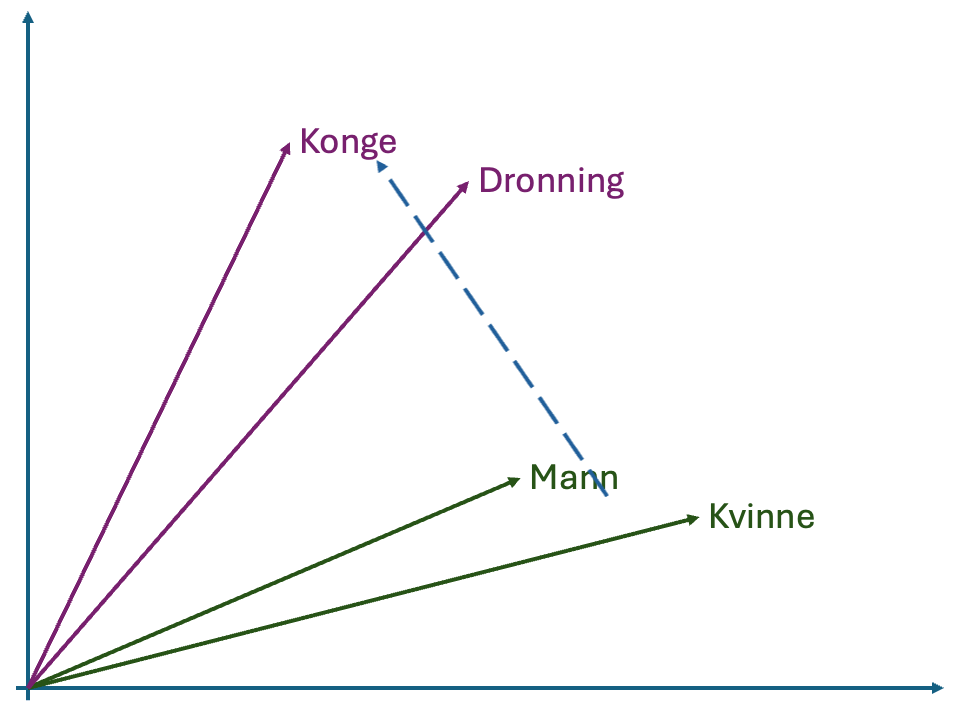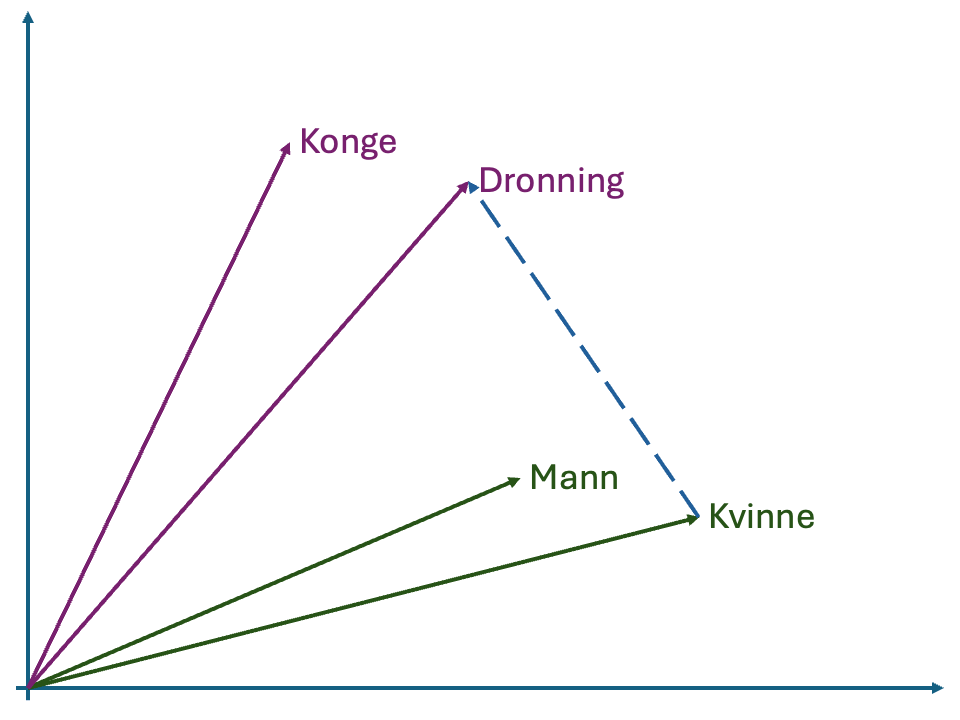
Mann og Konge som gir en vektor (striplet blå linje). Deretter legger vi denne vektoren til punktet Kvinne for å finne et ord som burde ha tilsvarende mening for kvinne.Et viktig poeng med embedding modeller er at de kan brukes på mer enn bare tekst, multimodale modeller kan også representere bilder, video og lyd. Hvis samme modell kan tolke flere forskjellige media kan man så bruke vektorene produsert for å sammenligne innholdet i forskjellige media.