9 Relevansvurdering (grading)
9.1 Bakgrunn og definisjon
I et standard KBS-system hentes vanligvis et fast antall dokumenter per søk. Disse topp n mest relevante dokumentene legges ved som kontekst til språkmodellen, som deretter bruker dem for å besvare brukerens spørsmål.
Med en slik tilnærming risikerer man at ikke alle de topp n dokumentene faktisk er relevante. Kanskje finnes det bare ett relevant dokument for det aktuelle spørsmålet, mens resten kun bidrar med støy.
Selv om moderne språkmodeller er ganske gode til å forstå hva som er relevant basert på konteksten de får, er det flere fordeler ved å filtrere søketreffene på forhånd. Denne filtreringen kalles “grading” og innebærer en vurdering av hvor relevante dokumentene er i forhold til det opprinnelige spørsmålet. Grading utføres vanligvis av en språkmodell og legges til som et steg i KBS-systemet mellom søket og svar-genereringen.
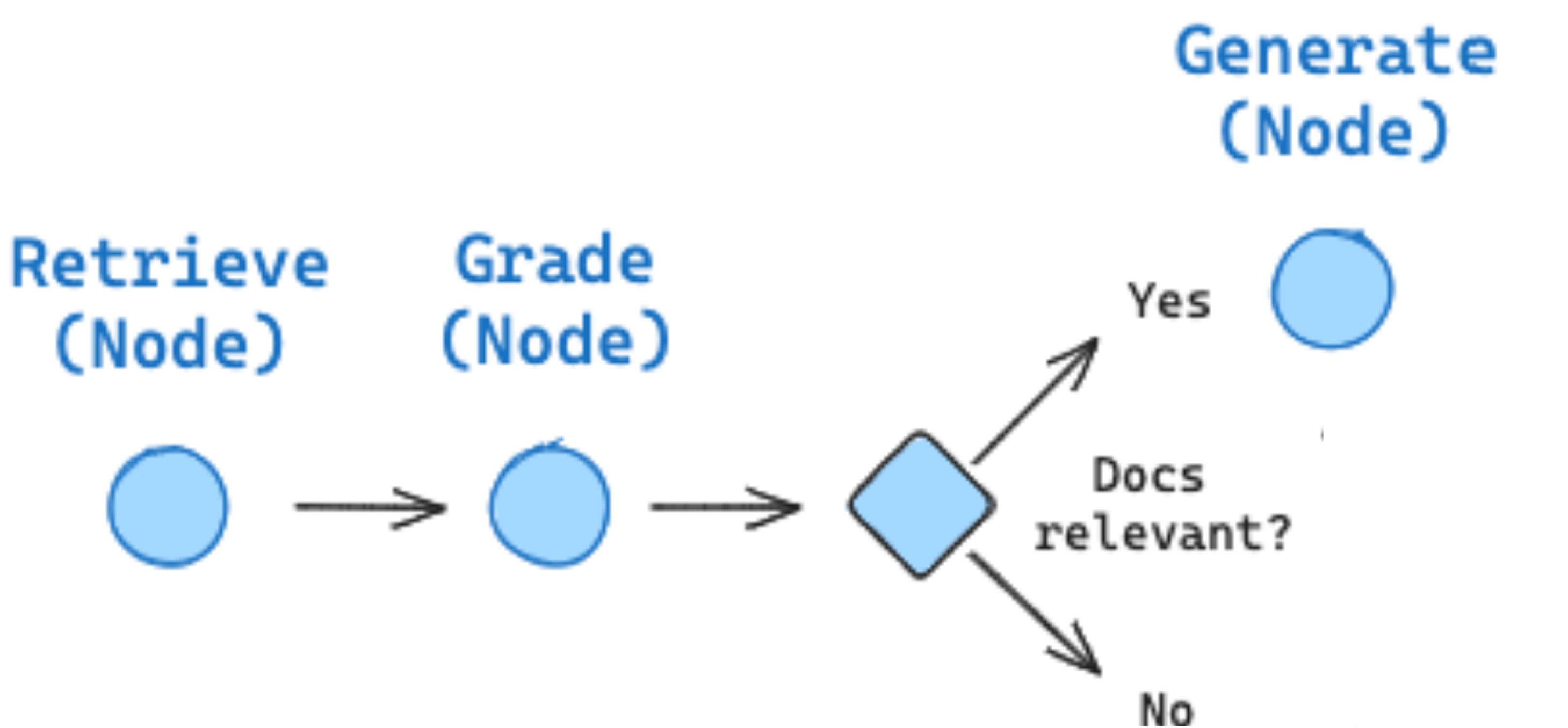
Fordeler med å inkludere grading i et KBS-system:
- Reduserer risikoen for at språkmodellen blir forvirret av irrelevant informasjon.
- Selv om grading innebærer noen ekstra kall til en språkmodell, kan det likevel redusere kostnader. Vår erfaring er at en mindre språkmodell kan gjøre gradingen, og at dette totalt sett blir billigere enn å bruke alle dokumentene som kontekst til den store språkmodellen som genererer svar.
Ulemper med å inkludere grading i et KBS-system:
- Introduserer et ekstra steg i flyten, så svartiden vil øke litt.
- Øker systemets kompleksitet; et ekstra steg som må implementeres og kvalitetssikres.
9.2 Hvordan implementere grading?
Målet med grading er å hjelpe systemet med å levere så relevante og presise svar som mulig, samtidig som vi må unngå å miste verdifull informasjon. Det er viktig å teste ulike instruksjoner på egne data for å finne riktig balanse i hvor strengt gradingen vurderer relevans. Du kan selv velge om gradingen skal være en enkel ja/nei-vurdering eller baseres på en mer nyansert skala.
Her følger et eksempel fra LangGraph på et grading-prompt som kan brukes som utgangspunkt:
You are a grader assessing relevance of a retrieved document to a user question. \
If the document contains keyword(s) or semantic meaning related to the question, \
grade it as relevant. \
Give a binary score 'yes' or 'no' to indicate whether the document is relevant \
to the question.Hva skjer hvis ingen dokumenter er relevante?
I noen tilfeller kan det hende at ingen av de innhentede dokumentene vurderes som relevante nok. Hva man bør gjøre i slike situasjoner avhenger av systemets kontekst. Noen mulige løsninger inkluderer:
- avbryte flyten og be brukeren om å omformulere spørsmålet eller gi mer kontekst
- la en språkmodell forsøke å omformulere spørsmålet og prøve på nytt. Se for eksempel Self-Reflective RAG (Self-RAG).
- gi systemet mulighet til å søke etter relevant informasjon på internett. Se for eksempel Corrective RAG (CRAG).
Man kan også falle tilbake på å sende alle søketreffene videre likevel.
9.2.1 LangGraph implementasjon
For å utvide kjøretidsgrafen som vi bygget i kapittel 7.1.3 er det bare å legge til grading som en egen node.
Først bygger vi en ChatPromptTemplate som kan benyttes av LangChain:
from langchain_core.prompts import ChatPromptTemplate
grade_prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
("human", "Retrieved document: \n\n {document} \n\n User question: {question}"),
]
)Deretter lager vi en funksjon som kan fungere som en node i LangGraph kjøretidsgrafen:
from langchain_openai import AzureChatOpenAI
from pydantic import BaseModel, Field
from typing import Literal, cast
# Data modell
class GradeDocuments(BaseModel):
"""Binær relevans-score for søketreffene."""
binary_score: Literal["yes", "no"] = Field(
description="Document is relevant to the question, 'yes' or 'no'"
)
llm = AzureChatOpenAI()
structured_llm_grader = llm.with_structured_output(GradeDocuments)
retrieval_grader = grade_prompt | structured_llm_grader
def grade_documents(state):
question = state["question"]
documents = state["context"]
# Kjører vurdering av dokumentene i parallell
inputs = [{"question": question, "document": doc} for doc in documents]
grades = await _grading_component.abatch(inputs)
filtered_context = []
for doc, grade in zip(documents, grades):
grade = cast(GradeDocuments, grade)
if grade.binary_score == "yes":
filtered_context.append(doc)
return {"context": filtered_context}Så kan vi oppdatere kjøretidsgrafen med den nye noden:
from langgraph.graph import END, START, StateGraph
# Vi benytter her tilstanden vi definerte i starten som grunnlag for grafen
workflow = StateGraph(GraphState)
# Legg til noder i grafen
workflow.add_node(retrieve)
workflow.add_node(grade_documents)
workflow.add_node("rag", generator)
# Definer hvordan nodene henger sammen
workflow.add_edge(START, "retrieve")
workflow.add_edge("retrieve", "grade_documents")
workflow.add_edge("grade_documents", "rag")
workflow.add_edge("rag", END)
# Kompiler grafen
app = workflow.compile()For å holde eksempelet enkelt har vi valgt å ikke legge inn noen håndtering av tilfellet der ingen dokumenter vurderes som relevante.