8 Kontekstuell informasjonsinnhenting
I Kapittel 5 beskrev vi hvordan vi vanligvis deler opp dokumentene i et KBS-system i mindre biter før vi laster dem opp til vektordatabasen. Dette gjøres både fordi embeddingmodellene har begrensninger på inputstørrelse, og fordi vi ønsker å skille ut semantisk ulike deler, slik at vektorsøket blir mer presist. Men ved slik oppsplitting er det også risiko for at noen segmenter mister viktige deler av konteksten sin.
I dette kapittelet går vi gjennom noen avanserte teknikker innen informasjonsinnhenting som kan bidra til å bevare kontekst som ellers kan gå tapt når dokumenter splittes opp i mindre deler.
“Kontekstuell informasjonsinnhenting” er en oversettelse av begrepet “contextual retrieval”. Søker du på dette, vil du antakelig finne en artikkel fra Anthropic fra september 2024. Artikkelen kan gi inntrykk av at “contextual retrieval” er en ny metode som Anthropic har utviklet. Selv om den spesifikke implementasjonen som Anthropic beskriver kanskje er ny, ser vi på “contextual retrieval” som et paraplybegrep som dekker ulike teknikker for å tilføre eller bevare kontekst ved informasjonsinnhenting.
Andre navn som brukes på disse teknikkene kan være “context enrichment techniques” (kontekstutvidende teknikker) eller mer overordnet “advanced RAG techniques” (avanserte KBS-teknikker).
8.1 Utfordringen med oppsplitting av dokumenter
La oss ta utgangspunkt i NKS sin kunnskapsbase for å illustrere problemstillingen. Selv om artiklene der er godt strukturert med seksjoner og underoverskrifter som gir naturlige inndelinger av teksten, er det likevel noen avsnitt som er for lange og må splittes opp.
Enkelte tekstbiter kan bli skilt fra sin tilhørende underoverskrift og dermed miste viktig kontekst. Dette kan føre til at vektorrepresentasjonen av teksten blir mindre presis, og i noen tilfeller kan bitene til og med bli direkte misvisende når de tas ut av sin opprinnelige sammenheng.
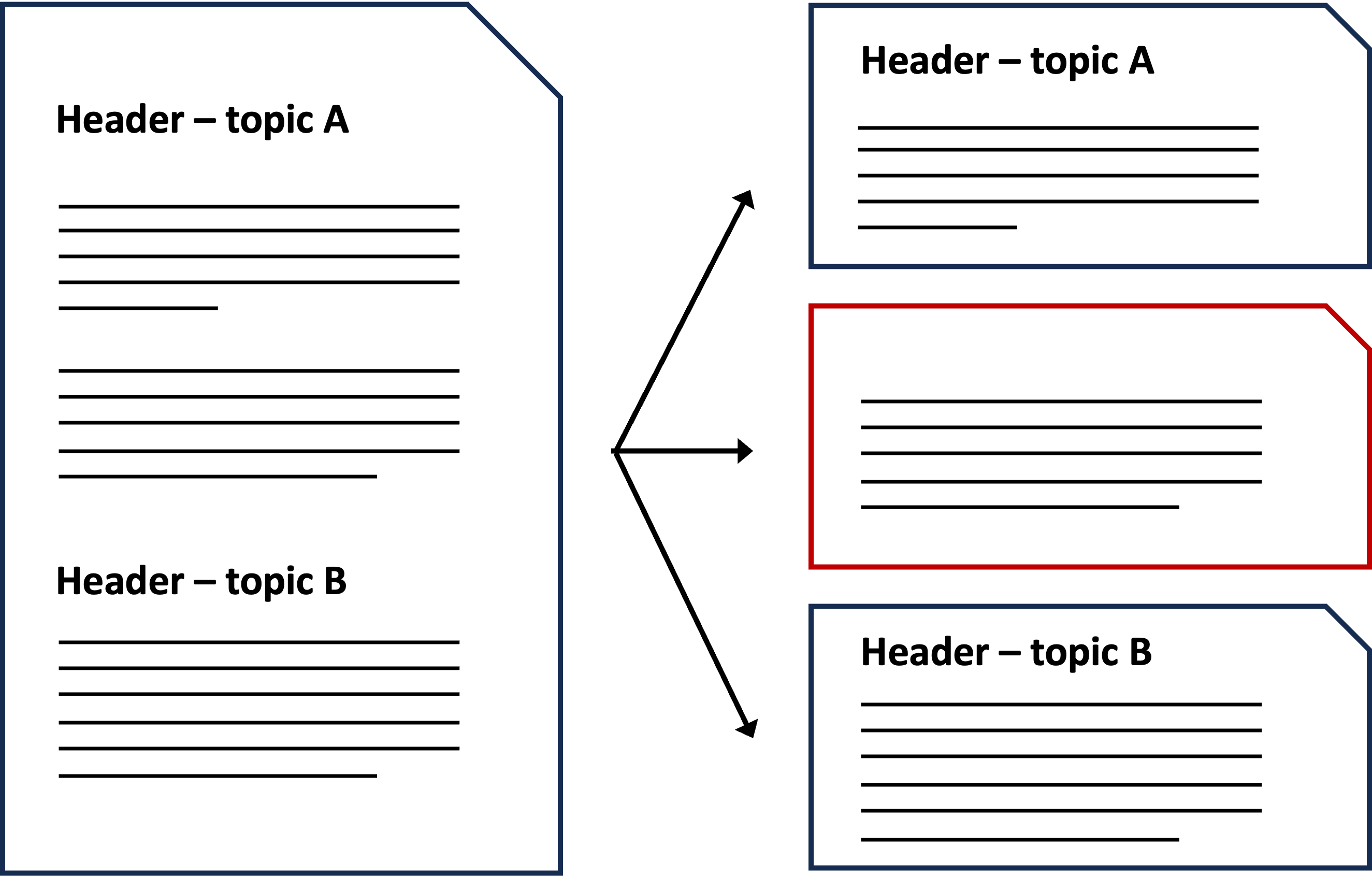
Dette er en kjent utfordring for mange som har utviklet KBS-systemer, men det er viktig å påpeke at dette ikke nødvendigvis er et problem i alle slike systemer. Problemet avhenger i stor grad av hvordan kunnskapsbasen er strukturert.
8.2 Teknikker for kontekstuell informasjonsinnhenting
Hvis du har utfordringer med tekstbiter som mangler viktig kontekst, finnes det flere tilnærminger for å håndtere dette. I dette kapittelet har vi valgt å begrense scopet til metoder for å bedre tilrettelegge og indeksere dokumenter for vektorsøk.
Det finnes også metoder som retter seg mot andre deler av KBS-systemet enn selve dokumentene. Vi går ikke nærmere inn på disse her, men noen av dem kan likevel være verdt å nevne:
- Legge til kontekst ved å kombinere tekstsøk og vektorsøk (hybridsøk). Hybridsøk gjør det mulig å supplere vektorsøket med tekstsøk basert på metadata. Se Seksjon 1.2.1 og Vedlegg C for mer informasjon om hybdridsøk.
- Bevare mer kontekst ved å justere hvordan man embedder, for eksempel gjennom fine tuning av embeddingmodellen eller ved å bruke teknikker som colBERT eller late chunking.
Dette er ikke en uttømmende liste over alle relevante metoder, men vi har valgt ut noen former for kontekstuell informasjonsinnhenting som vi ønsker å beskrive nærmere:
Tilføre kontekst i tekstbitene
Disse teknikkene handler om å legge til ekstra informasjon i hvert tekstbit, slik at viktig kontekst alltid blir inkludert.Bevare kontekst ved å kombinere ulike granularitetsnivå
Disse teknikkene bruker større deler av dokumentene sammen med mindre tekstbiter, slik at overordnet kontekst bedre ivaretas i søket.
8.2.1 Tilføre kontekst i tekstbitene
Den første strategien vi skal se på handler om å endre tekstbitene slik at de inneholder mer kontekst enn ved standard dokumentsplitting.
Disse teknikkene kalles ofte “chunk augmentation techniques” på engelsk, men det finnes også andre betegnelser, som:
- contextual chunk headers
- context-enriched chunking
- document enrichment
- chunking with context
- metadata attachment
- chunk dreaming
Uansett hva vi velger å kalle det, har alle metodene samme mål - å tilføre ekstra kontekstuell informasjon til hver tekstbit. Forskjellen melllom dem ligger som regel i:
- hvilken type informasjon man legger til i tekstbitene
- hvordan denne informasjonen integreres
8.2.1.1 Hvilken type kontekstuell informasjon kan vi bruke?
Kontekstuell informasjon vil ofte være en form for metadata. Noen eksempler på enkle metadata er:
- Dokumenttittel
- Tittel på underoverskrifter
- Nøkkelord som beskriver tema eller emne
- Kilde eller type dokument
Hvis dokumentene mangler metadata kan du få hjelp fra en språkmodell til å generere dette. I tillegg til de enkle formene for metadata nevnt ovenfor kan for eksempel en språkmodell lage oppsummeringer på ulike nivåer:
- Oppsummering av hele dokumentet
- Oppsummering av «sub-dokument» (et mellomnivå mellom hele dokumentet og mindre tekstbitet). Se for eksempel denne implementasjonen fra LlamaIndex
- “Sliding window”-oppsummeringer, hvor hver tekstbit får en kontekstoppsummering basert på de
nnærmeste tekstbitene, for eksempel forrige og neste tekstbit.
LlamaIndex har laget en guide som viser hvordan man kan definere ulike språkmodellbaserte Metadata Extractors. I tillegg til oppsummeringer gir guiden eksempler på andre typer kontekst en språkmodell kan trekke ut, som for eksempel “Spørsmål denne biten kan besvare” (Questions answered).
Anthropic har beskrevet sin egen tilnærming til contextual retrieval i en bloggpost. De bruker en språkmodell til å omformulere hver tekstbit slik at den settes i kontekst av resten av dokumentet. Denne metoden ligner på å bruke oppsummeringer som kontekstuell informasjon, men den går et steg videre ved å gi hver tekstbit sin egen, tilpassede kontekst.
Det finnes ingen omforent “beste praksis” for hvilke metadata som gir best resultater. Hva som fungerer best avhenger både av dokumentenes innhold og struktur, teknikken som brukes og hva slags inputspørsmål som skal besvares.
8.2.1.2 Hvordan kan vi tilføre konteksten?
Det finnes flere måter å legge til metadata før opplasting til vektordatabasen.
Den enkleste metoden er å lime inn den ekstra konteksten, som for eksempel overskrifter eller oppsummeringer, direkte i hver tekstbit før du genrerer embeddings.
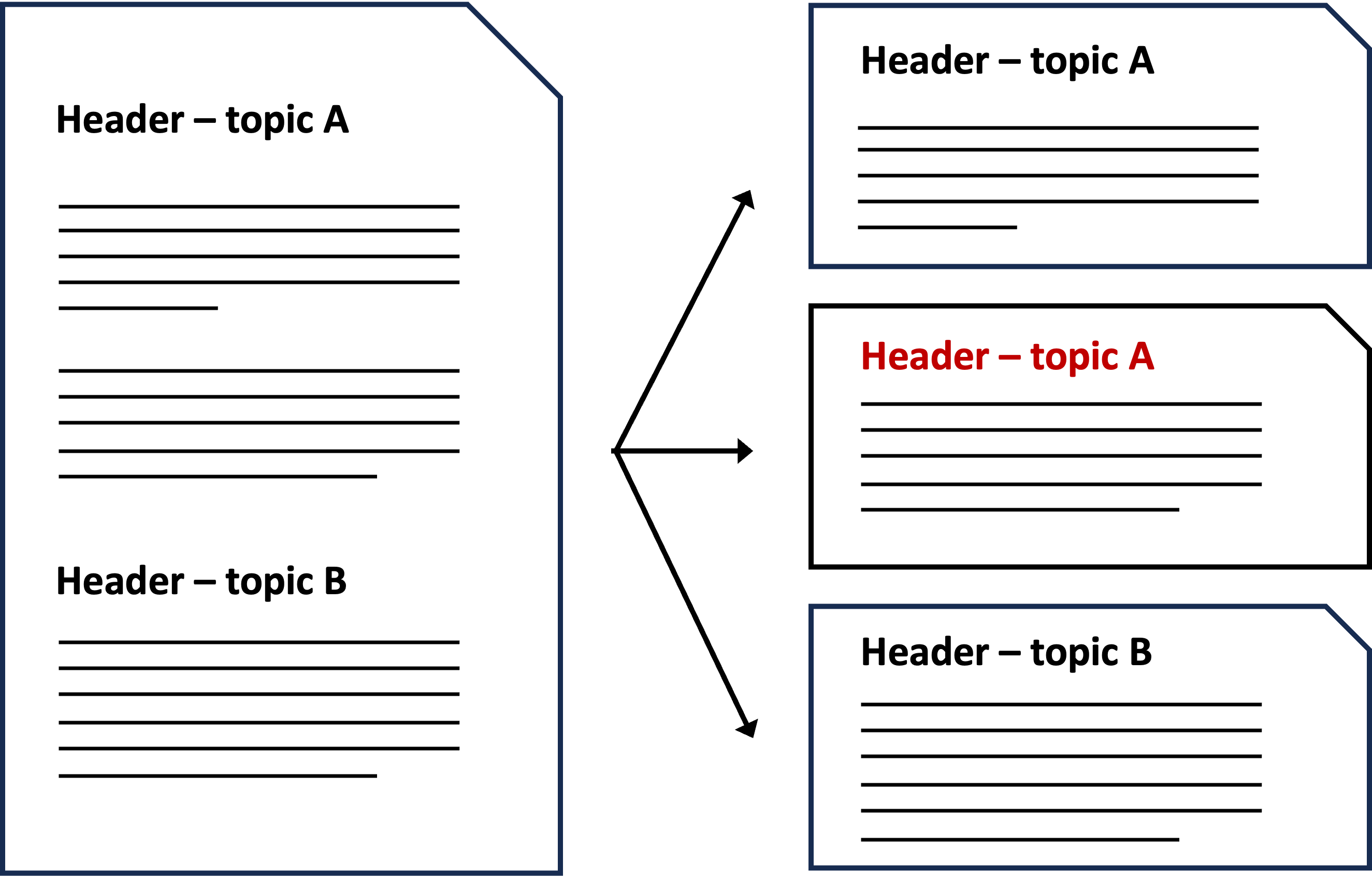
Tekstbiter med ekstra kontekst kan brukes både til vektorsøk og til mer tradisjonelle tekstsøk – eller til en kombinasjon av begge (hybridsøk). I den nevnte artikkelen om contextual retrieval fra Anthropic beskriver de hvordan denne tilnærmingen ga dem bedre resultater enn vektorsøk alene på tekstbiter med ekstra kontekst og overgikk også hybridsøk på tekstbiter uten ekstra kontekst.
En annen metode er å lage en embedding for hvert metadataelement du vil bruke og deretter beregne en vektet sum av disse, kalt en “sammensatt embedding” (composite embedding). Denne teknikken er f.eks. beskrevet nærmere i en bloggpost fra Elasticsearch.
En ulempe med å tilføre ekstra kontekst, uansett metode, er at hver tekstbit blir lenger. Dette kan bety at du må redusere den opprinnelige lengden på hver tekstbit for å få plass til den ekstra konteksten og samtidig holde deg innenfor modellens inputstørrelse-begrensinger. Den ekstra informasjonen vil også øke kostnadene, siden flere ord må behandles av både embeddingmodellen og språkmodellen.
Avhengig av hvilken teknikk du velger kan det være nyttig å vurdere prompt caching (også kjent som context caching). Med prompt caching kan du unngå å mate inn den samme informasjonen til modellen gjentatte ganger. Prompt caching tilbys av begge de to odelltilbyderne som Nav har mulighet til å bruke (Azure OpenAI, Google).
8.2.2 Bevare kontekst ved å kombinere ulike granularitetsnivå
Den andre gruppen av teknikker for kontekstuell informasjonsinnhenting som vi skal se på handler om å bevare mer av konteksten ved å balansere informasjon på overordnet nivå og tekstbit-nivå. Disse metodene kan også omtales som “multi- representation” indeksering, fordi de bruker flere vektorrepresentasjoner av samme dokument med ulik grad av detaljer.
8.2.3 Parent document indeksering
Parent document indeksering er en teknikk der man søker etter tekstbiter som vanlig, men i stedet for å returnere kun de mest relevante tekstbitene, henter man hele eller større deler dokumentene som bitene kommer fra. Det er altså en enkel metode for å få inkludert mer kontekst i informasjonen som oversendes til språkmodellen.
En ulempe med denne metoden er at den ikke er så presis. Det kan hende at mye av den ekstra informasjonen som returneres ikke er relevant for inputspørsmålet. I tillegg blir det mer tekst for språkmodellen å behandle for hvert spørsmål.
For et eksempel på hvordan denne teknikken kan implementeres, se dokumentasjonen til LangChain.
8.2.3.1 Hierarkisk indeksering
Hierarkisk indeksering går ut på å starte med søk på overordnet nivå, for deretter å fortsette søket på mer detaljerte nivåer. Denne metoden kan også kalles “layered indexing” eller “multi-stage indexing”.
Hvis dokumentene dine allerede har en hierarkisk struktur, kan det være naturlig å ta utgangspunkt i denne. For eksempel kan et dokument være organisert slik:
- Dokument
- Kapittel
- Seksjon
- Avsnitt
Da er det mulig å sette opp en søkesekvens som starter på det øverste nivået (dokument) og deretter går videre til mer detaljerte nivåer. Det er imidlertid ikke nødvendig å bruke alle hierarkinivåene i et dokument, selv om de finnes. Ofte kan det kanskje være nok med to nivåer: først et søk på overordnet nivå, deretter et søk på avsnitt-nivå. På avsnitt-nivå omfatter søket kun de avsnittene som tilhører dokumentene du fant på det overordnede nivået. Hvis det ikke er for mange avsnitt per dokument kan du vurdere å returnere alle avsnitt uten å utføre et nytt søk.
Det finnes ingen “one size fits all” med tanke på hvilket detaljnivå det er best å implementere i praksis. Hva som fungerer best avhenger både av strukturen på dokumentene dine og detaljeringsnivået på spørsmålene systemet skal svare på.
8.2.3.2 Indeksering av oppsummeringer
Hvis dokumentene dine mangler en fast hierarkisk struktur, eller teksten på de overorndede nivåene er for lang, kan du bruke bruke en språkmodell til å lage oppsummeringer. Disse kan deretter indekseres i stedet for hele teksten på de overordnede nivåene. Denne grenen av hierarkisk indeksering kalles ofte for “summary indexing” eller “summary embeddings”.
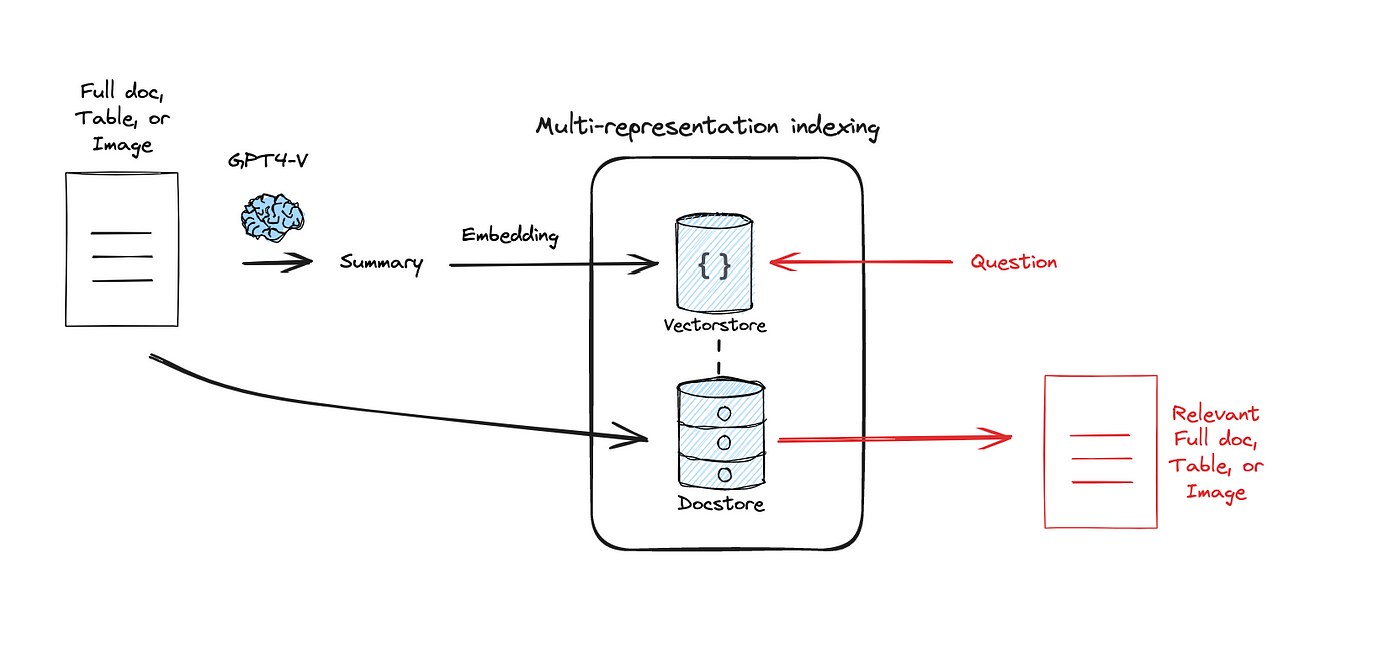
En ulempe med metoden er at det å holde vektordatabasen oppdatert også vil kreve jevnlig oppdaterte oppsummeringer. Dette kan potensielt medføre en del ekstra kostnader, avhengig av antall dokumenter og hvor hyppig de endres.
Her kan du finne et eksempel på hvordan denne teknikken kan implementeres med LangChain.
8.2.3.3 RAPTOR
RAPTOR er en avansert variant av hierarkisk indeksering utviklet ved Stanford. RAPTOR står for “Recursive Abstractive Processing for Tree-Organized Retrieval”. Kort fortalt handler denne metoden om å lage vektorrepresentasjoner av dokumenter, gruppere dem i klynger (clustre dem) og lage oppsummeringer av hver klynge. Dette gjøres rekursivt, slik oppsummeringene danner et hierarki av stadig mer overordnede konsepter. Resultatet er vektorrepresentasjoner av kunnskapsbasen din som i teorien skal dekke alt fra detaljerte til mer overordnede inputspørsmål.

En nedside med metoden er at den er relativt beregningskrevende, spesielt hvis du har en stor kunnskapsbase. For en full beskrivelse av metoden anbefales det å lese artikkelen der metoden først ble beskrevet.
8.3 Oppsummering
Ved å ta i bruk teknikker for kontekstuell informasjonsinnhenting, kan man oppnå forbedret nøyaktighet og relevans i svarene fra KBS-systemet. I denne artikkelen har vi sett at det finnes mange ulike varianter av slike teknikker. Hvilke som fungerer best i hvert enkelt case avhenger mye av hvordan dataene dine ser ut, og det kreves som regel en del eksperimentering for å finne ut hva som gir de beste resultatene.
For en beskrivelse av hva vi har testet ut av teknikker for NKS Kunnskapsbasen, se denne datafortellingen (Nav-intern).