# Prøv å bruke `rich.print` som standard hvis tilgjengelig
try:
from rich import print
except ModuleNotFoundError:
passFinjustere språkmodeller på Nav.no
I denne notatboken skal vi illustrere hvordan man kan komme i gang med finjustering av språkmodeller. Vi skal gå gjennom stegene for å gjøre klart et datasett basert på data på datamarkedsplassen (Nav-intern). Hvordan teste ytelsen på en embeddingmodell på dette datasettet. Og tilslutt, skal vi se hvordan vi kan forbedre ytelsen med finjustering.
Nødvendig maskinvare
Merk at oppsettet i denne notatboken ble testet med en Nvidia A100 GPU, tilgjengelig på GCP. Fordi modellen vi benytter har et relativt stort kontekstvindu så er det vanskelig å tilpasse trening på en lokal maskin.
For å provisjonere en maskin med GPU på GCP fulgte vi veiledningen til TryggTekst, men valgte en kraftigere GPU enn det de anbefaler.
Prosjektoppsett
Vi anbefaler at man bruker uv for å opprette prosjekt og styre avhengigheter.
La oss starte med å lage et prosjekt:
uv init --app --python 3.12 navno-finetuneInne i prosjektet kan vi fjerne main.py (eller hello.py avhengig av din versjon av uv). Hvis du ønsker å følge denne veiledningen kan man enkelt opprettet en Jupyter Notebook fil og klippe og lime kode fra veiledningen. Alternativt kan man strukturere kode etter eget ønske og bruke veiledningen til inspirasjon.
Tilgang til denne notatboken
Du kan laste ned notatboken denne datafortellingen er basert på, på Github.
Valgfrie avhengigheter
For å gjøre livet litt mer fargerikt installerer vi rich, dette er ikke nødvendig, men vil gi penere utskrift.
uv add richDatasett
Før vi kan starte å finjustere trenger vi et datasett vi kan teste på og som vi kan bruke til trening. Vi kommer til å benytte innholdet på Nav.no som utgangspunkt.
Laste ned rådata
La oss starte med å laste ned rådata fra BigQuery. For å gjøre dette kommer vi til å bruke google-cloud-bigquery og Polars.
Nødvendige avhengigheter
For å installere avhengigheter kjører vi følgende uv kommandoer:
uv add google-cloud-bigquery
uv add polars --extra pyarrowVi starter med å hente all rådata og opprette en Polars DataFrame.
import polars as pl
from google.cloud import bigquery
client = bigquery.Client()
# Bygg opp spørring og hent all data for gitt tidspunkt
QUERY = (
"SELECT * FROM `nks-aiautomatisering-prod-194a.navno_crawl.navno` "
"WHERE DATE(crawl_date) = DATE(2025, 02, 25)"
)
query_job = client.query(QUERY)
rows = query_job.result() # Vent på nedlasting
df = pl.from_arrow(rows.to_arrow()) # Opprett dataframe med rådataLa oss inspisere dataene, før vi konverterer det til et mer passende format for språkmodeller.
df.head()Strukturere data for språkmodeller
For å finjustere en embeddingmodell er det i hovedsak fire ulike måter å strukturere et datasett:
- Positive pair: Et par setninger som er relatert (f.eks
(spørsmål, svar)). - Triplets: Likt som positive pair, men med et anti-relatert element.
- Fordi vi kan bruke treningsfunksjoner (loss-funksjon) som kan gjennbruke data i positiv pair datasettet er ikke dette formatet like mye brukt.
- Pair with Similarity Score: Et par setninger og en verdi som representerer hvor like disse setningene er.
- Text with Classes: En setning med tilhørende klasse. Kan konverteres til andre formater over.
Hentet fra SBERT.net - Dataset Overview.
Basert på dataene over så er det naturlig å velge Positiv Pair. Dette er fordi vi kan koble flere kolonner sammen for å lage disse parene. Vi kan for eksempel koble tittel og innhold sammen, noe som burde forsterke koblingen mellom tittel og relevant innhold for språkmodellen.
Merk at vi setter innholdet til å være vårt anchor og tittelen til å være positive. Dette gjør vi fordi vi ønsker at systemet skal lage en embedding av innholdet som så skal knyttes til tittelen.
La oss starte med det åpenbare (tittel, innhold) paret
relevant_combinations = []df_all_titles_content = df.select(
(pl.col("headers").list.join(separator="\n") + "\n" + pl.col("content")).alias(
"anchor"
),
pl.col("display_name").alias("positive"),
)
relevant_combinations.append(df_all_titles_content)
df_all_titles_content.head()En annen åpenbar kobling er (tittel, ingress)
df_title_ingres = (
df.filter(pl.col("ingress").str.len_bytes() > 0)
.select(
pl.col("ingress").alias("anchor"),
pl.col("display_name").alias("positive"),
)
.unique()
)
relevant_combinations.append(df_title_ingres)
df_title_ingres.head()df_title_headers = df.filter(pl.col("headers").list.len() > 0).select(
pl.col("headers").list.join(separator="\n").alias("anchor"),
pl.col("display_name").alias("positive"),
)
relevant_combinations.append(df_title_headers)
df_title_headers.head()La oss koble alle disse tabellene sammen og for å lage et endelig datasett.
df_train = pl.concat(relevant_combinations)
df_train.head()Rense datasett
Før vi sier oss fornøyd skal vi vaske dataene våre litt. I tabellene over har du kanskje lagt merke til at flere av kolonnene inneholder HTML elementer. Det er ikke i utgangspunktet noe galt å bruke dette for trening, men siden vi her fokuserer på en embeddingmodell ønsker vi at den fokuserer på semantikken og ikke formatet. Vi skal derfor prøve å renske bort alle HTML tag-er1.
df_train = df_train.with_columns(
pl.col("anchor").str.replace_all("<.*?>", " ").str.strip_chars(),
pl.col("positive").str.replace_all("<.*?>", " ").str.strip_chars(),
)
df_train.head()Lagre til fil
La oss avslutte med å lagre data til en fil slik at vi enkelt kan gjenskape treningen og samtidig dele data med andre på en enkel måte. Et format som kan være praktisk er Parquet som både er effektivt for å lagre dataframe data og samtidig er godt støttet i de fleste verktøy vi bruker i Nav.
df_train.write_parquet("dataset.parquet")
Overgang til
datasets
Avhengig av dine preferanser så er dette et naturlig tidspunkt å gå over til datasets. datasets er et bibliotek for datasett som er veldig mye brukt med språkmodeller og 🤗 Hugging Face. Vi kommer til å laste inn datasets litt senere da treningsmetoden vi skal benytte bruker dette biblioteket.
I denne datafortellingen kommer vi til å holde oss til Polars så lenge som mulig på grunn av tidligere kjennskap til Polars samt at vi fortsatt trenger noen operasjoner som vil være raskere i Polars enn i datasets.
Trening og test
Nå som vi har laget et fullstendig treningssett kan vi begynne å tenke på å dele opp i en trenings del og en test del. Dette gjør vi for å ha en del som modellen får lov til å se på, trenings delen, og en del som er helt ny for modellen, test delen. Ved å skille slik får vi mulighet til å evaluere hvor godt modellen fungerer på ting den ikke har sett før.
Vi starter med å legge til en ID kolonne på datasettet vårt slik at vi kan unikt identifisere rader, dette kommer vi til å trenge senere.
dataset = df_train.with_row_index("id")Deretter deler vi datasettet i en del for trening, meste parten, og en del for testing.
# Litt komplisert å lage trening/test split i Polars
#
# Vi starter med å randomisere hele datasettet
dataset = dataset.sample(fraction=1, shuffle=True, seed=12345)
# Beregne antall rader vi skal bruke
num_test = int(0.1 * len(dataset))
# Deretter ta de første `num_test` radene til test
test_dataset = dataset.head(num_test)
# Tilslutt tar vi alle utenom de første `num_test` radene til trening
train_dataset = dataset.tail(-num_test)For å kunne reprodusere eksperimentene på andre maskiner lagrer vi også trening og test data som egne filer.
test_dataset.write_parquet("test_dataset.parquet")
train_dataset.write_parquet("train_dataset.parquet")Corpus
Nå som vi har opprettet et datasett kan vi bruke dette for å lage oss et corpus å trene på/med.
Vi starter med å lage oss et sett med alt innhold, “corpus”, og et sett med “queries” (de elementene som vi ønsker å teste mot innholdet).
# Merk at vi bruker `dataset` for å bruke _alt_ innhold
corpus = dict(dataset.select(["id", "positive"]).rows())
# For "queries" bruker vi det vi har plukket ut i test
queries = dict(test_dataset.select(["id", "anchor"]).rows())Vi trenger så å lage oss en mapping mellom “queries” og relevant innhold. I vårt tilfellet så vil det være overlapp for alle “queries” som mapper til samme tittel. Siden vi ønsker å knytte innhold sterkere til tittel så ønsker vi ikke at evalueringen skal strengt finne “samme tittel” så vi markerer alle ID-er med samme tittel som relevante.
relevant_docs = {}
for qid in queries.keys():
# Hvert "spørsmål" vil være knyttet til en tittel fra Nav.no, vi henter ut
# denne tittelen og henter alle rader i datasettet med samme tittel som
# relevant dokument
q_pos = (
dataset.filter(pl.col("id") == qid)
.unique("positive")
.item(row=0, column="positive")
)
relevant_docs[qid] = set([qid])
relevant_docs[qid].update(
set(dataset.filter(pl.col("positive") == q_pos).get_column("id"))
)Språkmodell
Nå som vi har ordnet oss med litt data er det endelig på tide å velge en språkmodell. Vi kommer til å bruke sentence-transformers for modellen og trening så la oss først ordne nødvendige pakker.
Nødvendige avhengigheter
Vi trenger et par pakker for sentence-transformers og de avhenger av riktig oppsett for effektiv trening.
For maskiner uten dedikert Nvidia GPU kan man enkelt installere som følger:
uv add transformers --extra torch
uv add sentence-transformers --extra trainHvis du har et dedikert grafikkort kan du tjene mye på å installere PyTorch med CUDA støtte.
Her anbefaler vi å følge oppskriften på PyTorch sin hjemmeside for å få riktig oppsett for akkurat din maskin.
Deretter trenger du:
uv add transformers
uv add sentence-transformers --extra trainFor å øke hastighet på treningen kan det være lurt å installere flash-attn som er en optimalisert versjon av Attention mekanismen i Transformer nettverk. Dette vil gjøre finjusteringen raskere på støttet maskinvare (for det meste GPU-er).
uv add flash-attn --no-build-isolationNår det kommer til valg av språkmodell så er det vanskelig å gi noen konkrete anbefalinger, nettopp fordi man kan tilpasse modellene til egne data slik vi gjør her. En god oversikt over hvordan å velge språkmodell finnes i Nav sin tekniske veileder.
Vi kommer til å gå videre med Alibaba-NLP/gte-modernbert-base. Denne har vi valgt av følgende grunner:
- Den gjør det godt i sammenligninger mot embeddingmodeller av tilsvarende størrelse
- Det er en relativt liten, \(149\) millioner parametere, modell som burde passe fint på en laptop
- Den har et stort kontekstvindu på \(8192\) token
- Noe som betyr at den kan jobbe med større sammenhengende tekster
- Den er lisensiert på en måte som gjør at vi enkelt kan ta den i bruk i Nav (
Apache 2.0)
Deretter oppretter vi språkmodellen vår. Første gang dette gjøres kan det ta litt tid da modellen må lastes ned.
import torch
from sentence_transformers import SentenceTransformer
model = SentenceTransformer(
"Alibaba-NLP/gte-modernbert-base",
# NOTE: Vi velger `device` tilpasset CUDA, for Mac kan man bruke `mps` og
# `cpu` vil alltid være tilgjengelig
device="cuda" if torch.cuda.is_available() else "mps",
model_kwargs=dict(
attn_implementation="flash_attention_2"
if torch.cuda.is_available()
else "sdpa",
),
tokenizer_kwargs=dict(padding="max_length", truncation=True),
)Evaluere språkmodell
La oss nå se litt på hvordan modellen vår gjør det på datasettet vårt.
Vi må starte med å definere en måte å evaluere modellen vår, her har også sentence-transformers god støtte så vi benytter det som er innebygget der.
from sentence_transformers.evaluation import InformationRetrievalEvaluator
from sentence_transformers.util import cos_sim
evaluator = InformationRetrievalEvaluator(
queries=queries,
corpus=corpus,
relevant_docs=relevant_docs,
name="modernbert",
score_functions={"cosine": cos_sim},
batch_size=64
if torch.cuda.is_available()
else 4, # Skru denne ned eller opp avhengig av tilgjengelig minne, høyere gir raskere evaluering
show_progress_bar=True,
)Deretter kan vi benytte evaluator til å vurdere modellene vår.
base_eval = evaluator(model)Fra evalueringen over er det kanskje mest interessant å se på NDCG@10 som sier oss noe om kvaliteten på rangering av treff.
print(f"Rangeringskvalitet (NDCG@10): {base_eval['modernbert_cosine_ndcg@10']}")Finjustering
Etter at vi nå har valgt og testet en embeddingmodell er det nå på tide å se om vi kan forbedre ytelsen til modellen ved å finjustere.
Vi kommer til å holde oss i sentence-transformers verden og benytte treningsmetoder derfra.
Treningsmetode (loss function)
Før vi kan finjustere språkmodellen vår må vi definere en treningsmetode som forteller systemet hvor bra, eller dårlig, modellen vår gjør det når vi presenterer den for eksempler.
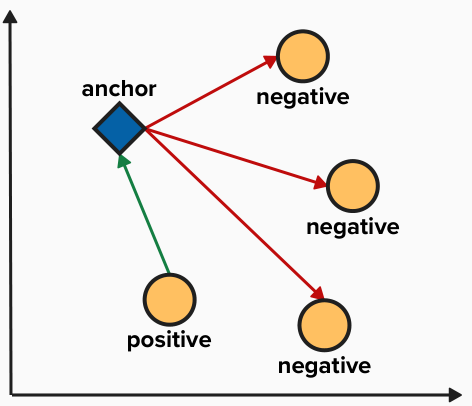
MultipleNegativeRankingLoss optimaliserer ved å knytte “nåværende” treningseksempel tettere og samtidig “skyve bort” alle andre eksemplerFor datasett av typen Positiv Pair er MultipleNegativesRankingLoss veldig passende fordi den kan gjenbruke “alle andre” eksempler i treningssettet som negative eksempler.
from sentence_transformers.losses import MultipleNegativesRankingLoss
train_loss = MultipleNegativesRankingLoss(model=model)Treningsoppsett
Etter at vi har definert en treningsmetode så må vi gjøre litt husarbeid for å definere hvordan trening skal foregå.
Nødvendige avhengigheter
Siden sentence-transformers bruker datasets for å strukturere treningseksempler trenger vi også dette biblioteket.
uv add datasetsfrom sentence_transformers import SentenceTransformerTrainingArguments
from sentence_transformers.training_args import BatchSamplers
# Definer hvordan trening skal foregå
train_args = SentenceTransformerTrainingArguments(
output_dir="gte-modernbert-navno",
num_train_epochs=4, # Antall epoker å trene, flere er bedre
per_device_train_batch_size=128, # Bestemt av maskinvare, høyere trener raskere
per_device_eval_batch_size=32,
warmup_ratio=0.1,
learning_rate=2e-5,
lr_scheduler_type="cosine",
optim="adamw_torch_fused",
tf32=True, # Kjekt å sette til `True` hvis maskinvare støtter (krever nyere Nvidia GPU)
fp16=False, # Sett til `True` hvis man ikke kan bruke `bf16`
bf16=True, # Kjekt å sette på hvis maskinvare støtter (støttes av Mac og Nvidia GPU-er)
batch_sampler=BatchSamplers.NO_DUPLICATES, # Veldig praktisk å fjerne duplikater når man har Positiv Pair
eval_on_start=True,
eval_strategy="epoch", # Evaluer etter hver X steg
save_strategy="epoch", # Lagre modell etter X steg
logging_steps=50,
save_total_limit=3, # Bare spar på de 3 siste modellene
load_best_model_at_end=True,
metric_for_best_model="modernbert_cosine_ndcg@10",
)Vi konverterer så treningsdataene våre til et datasets slik at det er kompatibelt med sentence-transformers.
from datasets import Dataset
train_ds = Dataset.from_polars(train_dataset.select(["anchor", "positive"]))
train_dsOgså kan vi sette opp treningsregimet vårt.
from sentence_transformers import SentenceTransformerTrainer
trainer = SentenceTransformerTrainer(
model=model,
args=train_args,
train_dataset=train_ds,
loss=train_loss,
evaluator=evaluator,
)Utføre finjustering
Med det unnagjort kan vi bare kjøre treningsregimet vårt for å få en finjustert modell.
# Utfør trening
trainer.train()
# Pass på at vi lagrer modellen
trainer.save_model()Evaluer finjustert modell
Nå som vi har finjustert modellen gjenstår det bare å evaluere om finjusteringen hadde noe for seg.
Vi kan gjenbruke evalueringen vi brukte tidligere, men det er lurt å laste modellen på nytt slik at vi er sikker på at vi evaluerer riktig modell.
import torch
from sentence_transformers import SentenceTransformer
model = SentenceTransformer(
# NOTE: Vi bytter ut modellnavn her med mappen hvor vi lagret den finjustert
# modellen
train_args.output_dir,
# NOTE: Vi velger `device` spesifikt tilpasset Mac, for Nvidia kan man bruke
# `cuda`, for de fleste andre formål er `cpu` riktig valg
device="cuda" if torch.cuda.is_available() else "cpu",
)final_eval = evaluator(model)La oss så se hvordan det gikk med finjustert modell.
print(f"Ikke finjustert\t(NDCG@10):\t{base_eval['modernbert_cosine_ndcg@10']}")
print(f"Finjustert\t(NDCG@10):\t{final_eval['modernbert_cosine_ndcg@10']}")Resultat av finjustering
| NDCG@10 | Forbedring | |
|---|---|---|
| Ikke finjustert | 0.219 | NA |
| Finjustert | 0.626 | 2.85x |
Merk
Den fantastiske fremgangen vi får kan ikke nødvendigvis bare tilskrives at vi er så flinke til å finjustere. Modellen vi har valgt er ikke trent på norsk språk så mye av fremgangen kan nok tilskrives at modellen både lærer vårt datasett, men også at den lærer norsk.
For denne datafortellingen var det viktigere å vise hvordan man kan komme i gang med å finjustere enn å velge den beste modellen.
Fotnoter
Vi gjør det enkelt med en
regexinspirert av StackOverflow.↩︎